Technologiczna strona rozwiązań - wgląd w systemy AI od Droplabs
Ten wpis jest jedną z części szerszego artykułu "AI w służbie dziedzictwa: Dynamic Pricing Droplabs i predykcja frekwencji w kształtowaniu zrównoważonych zachowań turystycznych w TPN". Część pierwsza opisuje biznesowy aspekt prognozowania frekwencji - zapraszamy do jej lektury!
TPN korzysta z mechanizmu Prognozowania frekwencji opartej o AI dostarczanej przez Droplabs w ramach systemu sprzedaży online z Dynamic Pricing. Prognozowanie frekwencji ma znaczenie dla efektywności zarządczej TPN, pomaga w planowaniu harmonogramu pracy Służby Parku (patrole) oraz optymalnym rozmieszczaniu i przygotowaniu personelu na poszczególnych placach postojowych. Ponadto, pomaga TPN-owi na bieżąco dostosowywać komunikaty informacyjne dla odwiedzających.
Tak jak zostało nakreślone w części pierwszej, kompleks parkingowy TPN, będący bramą do Morskiego Oka, jest infrastrukturą wieloelementową. Obejmuje on główny parking na Palenicy Białczańskiej (o pojemności ok. 600 miejsc), a także uzupełniający pas drogowy łączący Palenicę Białczańską z Łysą Polaną oraz utwardzony plac postojowy na Łysej Polanie.
Wgląd w Mechanizmy Technologiczne
Warto wyraźnie zaznaczyć, że mechanizm AI stworzony przez Droplabs bazuje na modelach uczenia maszynowego (machine learning), czyli fundamencie sztucznej inteligencji. Nie wykorzystuje on natomiast mechanizmów najczęściej obecnie kojarzonych z AI, takich jak duże modele językowe (LLM) znane z czatbotów (np. Gemini czy ChatGPT).
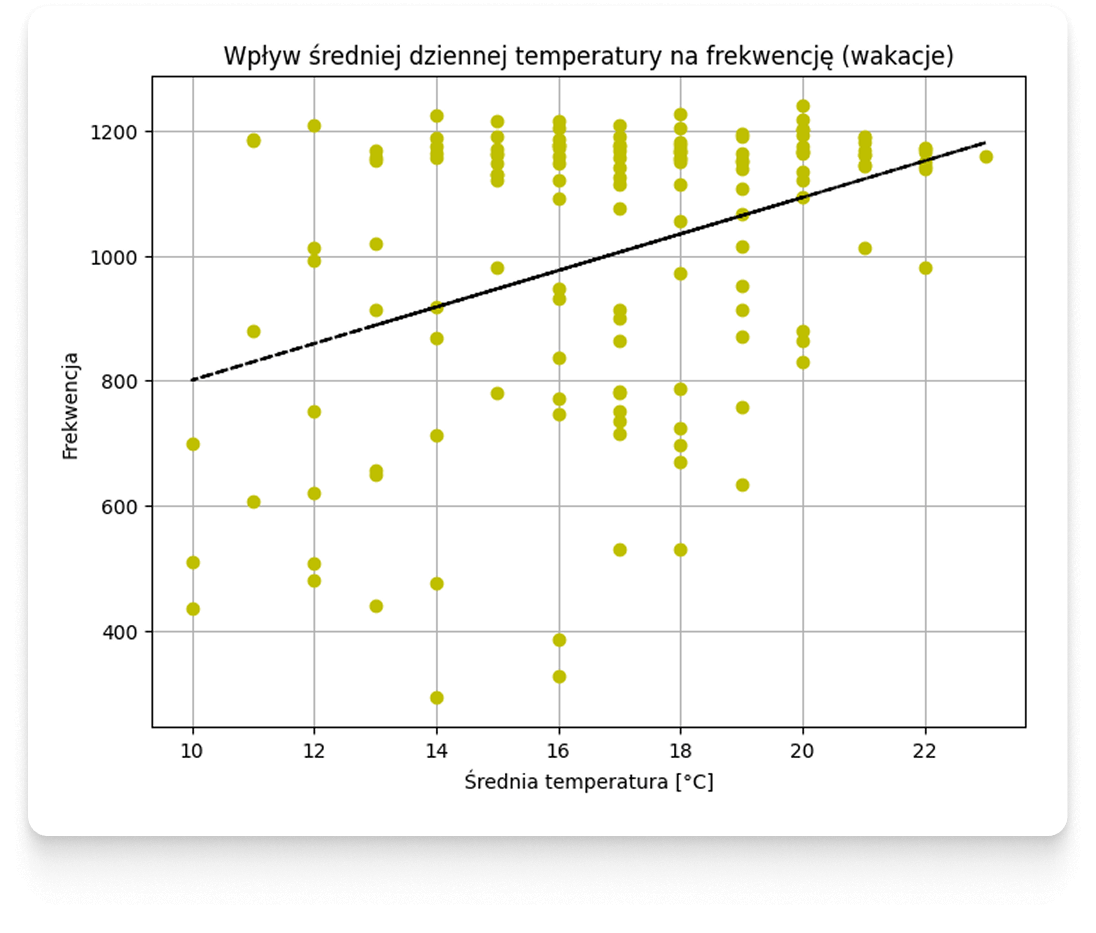
Chcąc zaglądnąć pod maskę stosowanych rozwiązań, zacznijmy od etapu, który rozpoczyna pracę nad modelem uczenia maszynowego czyli tzw. eksploracji danych. Przydatne są do tego między innymi wspomniane już w części pierwszej wykresy rozrzutu.
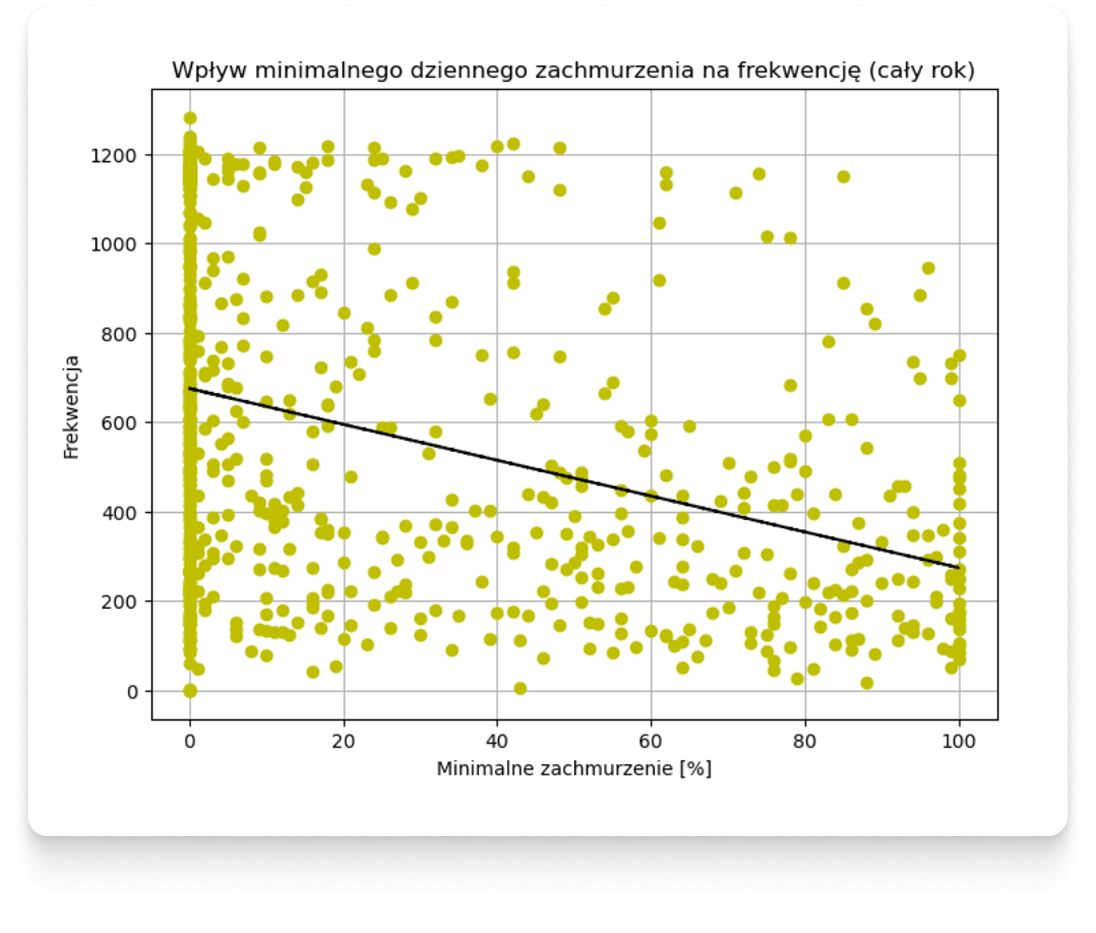
Wykresy rozrzutu pozwalają obalić hipotezę o prostych zależnościach pomiędzy pogodą a frekwencją.
Poniżej przedstawimy dodatkowe przykłady ilustrujące frekwencję na Parkingu Morskie Oko względem wyizolowanych pojedynczych cech pogodowych. Na wykresach zostały wykreślone czarną linią hipotetyczne przebiegi liniowe, których korelację określa współczynnik Pearsona - wykreślenie ich, nie oznacza oczywiście, że rzeczywiste zachowania klientów są liniowe - prowadząc taką analizę, w tym przypadku, omijamy inne rodzaje korelacji i zależności, które są analizowane innymi metodami w kolejnych krokach. Należy też pamiętać, że są to jedynie wybrane wizualizacje – w pełnym procesie analizy uwzględnia się cechy pochodzące z wielu różnych źródeł danych, a nie tylko prognozy meteorologiczne.

Podobnie jak wykresy rozrzutu pozwalają obalić hipotezy o prostych zależnościach pomiędzy pogodą a frekwencją, ale pomagają zapoznać się z charakterystyką danych, tak kolejna metoda używana w początkowych fazach prac nad modelami predykcyjnymi tj. analiza skupień - pozwala wyłapać różne zachowania klientów, pewne nieoczywiste zależności i podobieństwa pomiędzy terminami oraz znaleźć nietypowe punkty danych.

“Widoczne na wykresie grupy 1 i 3 – odpowiadają odpowiednio za zaplanowane i niezaplanowane podróże w sezonie letnim – to dni charakteryzujące się najwyższą roczną frekwencją. Ich mechanizmy zakupowe różnią się jednak istotnie: w grupie dni zaplanowanych około 80% biletów jest nabywanych z co najmniej jednodniowym wyprzedzeniem. W przypadku dni niezaplanowanych wartość ta spada poniżej 60%.
Analiza wykazuje, że ta rozbieżność jest kształtowana głównie przez warunki meteorologiczne. Klienci wykazują tendencję do planowania wizyt w dniach z przewidywaną sprzyjającą aurą. Co intrygujące, w dniach o mniej korzystnej prognozie frekwencja nie ulega znacznemu obniżeniu, lecz kluczowo zmienia się zachowanie klientów, którzy stają się bardziej spontaniczni, reagując na bieżące warunki (np. gdy przewidywany deszcz okazuje się jedynie poranną mżawką).”
- dodaje Michał Piłat Data Scientist z Droplabs
Architektura modelu i trenowanie
Mając wiedzę na temat charakterystyki danych, możliwe jest przejście do etapu wyboru modelu oraz architektury optymalnej dla rozwiązania problemu w ramach konkretnego horyzontu czasowego. Na tym etapie - dla każdego horyzontu predykcji sprawdzanych jest wiele różnych modeli machine learningu oraz konfiguracji danych. Skuteczność modelu oceniana jest za pomocą tzw. Confusion Matrix.
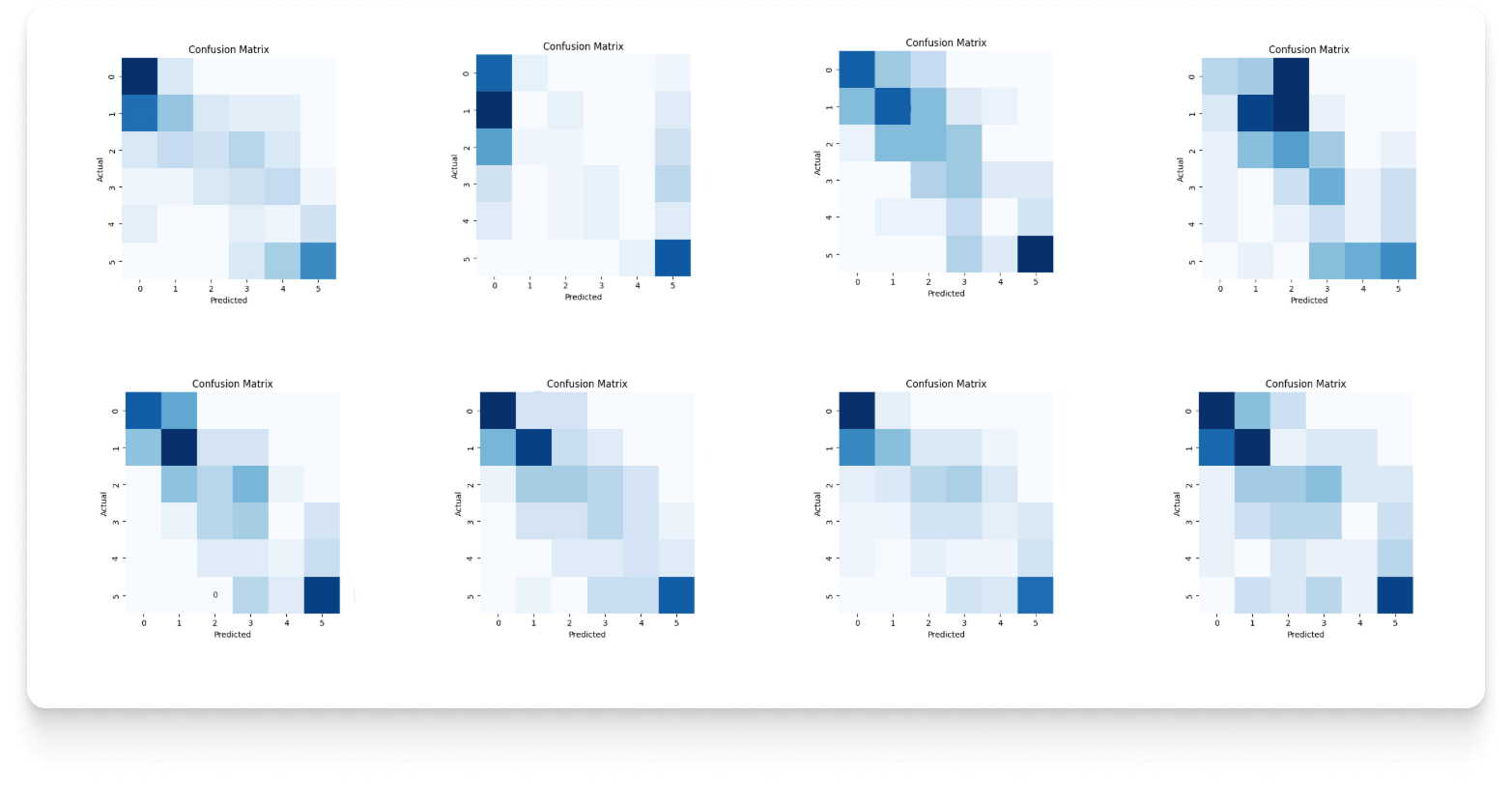
W drodze analizy skuteczności, za finalne rozwiązanie obrana została architektura z kategorii głębokich sieci neuronowych (deep neural networks).
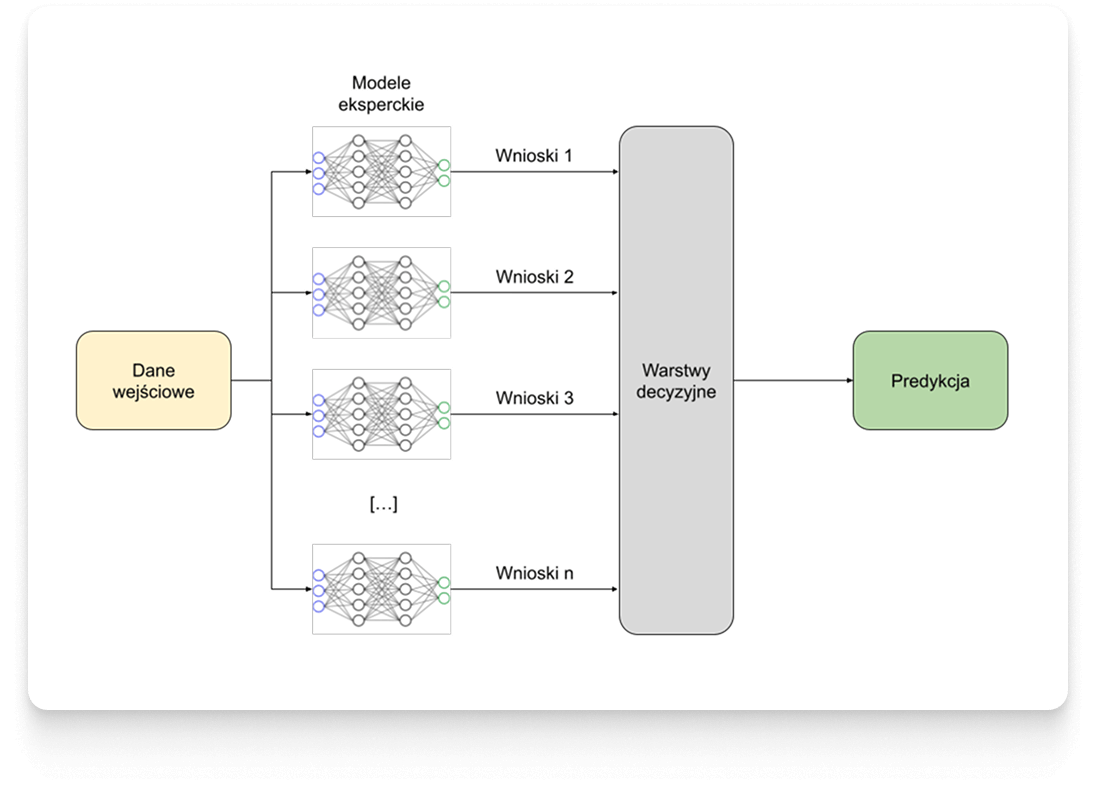
Modele uczenia głębokiego (deep learning) nie są standardowym podejściem dla typu danych, na których przyszło pracować. Badania i optymalizacja procesu prowadzone przez Zespół Droplabs, skłoniły do wybrania niestandardowej architektury łączącej cechy uczenia głębokiego oraz uczenia zespołowego (ensemble learning), czyli inteligentnym połączeniu wielu modułów. Droplabs uzyskuje w ten sposób “zespół ekspertów”, w którym każdy model specjalizuje się w innej dziedzinie, a ostateczna decyzja podejmowana jest na podstawie wniosków wyciągniętych przez wszystkie indywidualne komponenty.
Taka architektura daje Droplabs uniwersalne rozwiązanie, które może być dostosowywane do indywidualnych potrzeb danego obiektu wynikających z przeprowadzonej wcześniej eksploracji danych.
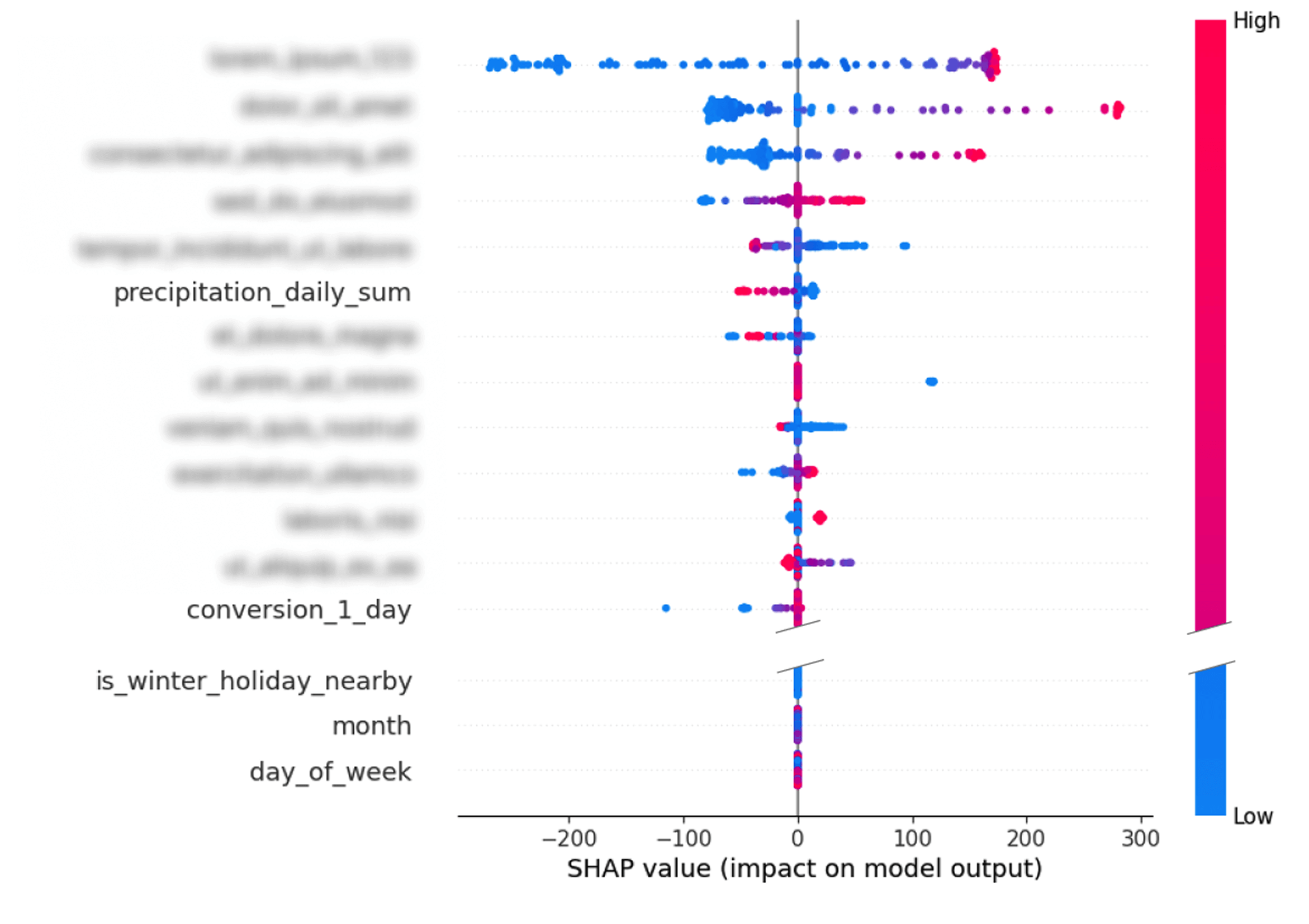
Po wyborze architektury modelu, rozpoczyna się kolejny ważny etap, czyli jego trenowanie. Istotne jest bowiem zrozumienie, że predykcja frekwencji dla nadchodzącego dnia stanowi problem analityczny różniący się od tworzenia prognozy na horyzont 3 czy 7 dni do przodu. W różnych sytuacjach dysponujemy różnymi zestawami dostępnych danych, które są kluczowe. Właśnie dlatego każdy horyzont predykcji jest traktowany jako odrębny model, który musi być niezależnie optymalizowany. Pierwszym zadaniem jest określenie optymalnych parametrów i selekcja cech. W tym celu Droplabs przeprowadza szczegółową analizę wrażliwości. Analiza ta pozwala precyzyjnie ustalić, w jakim stopniu poszczególne cechy wpływają na ostateczny wynik predykcji. Badanie to może być wykonywane zarówno dla konkretnych przypadków, jak i dla całego zbioru danych. W efekcie powstaje lista cech posortowana według siły ich wpływu na wynik predykcji, co umożliwia optymalne dostrojenie każdego modelu.
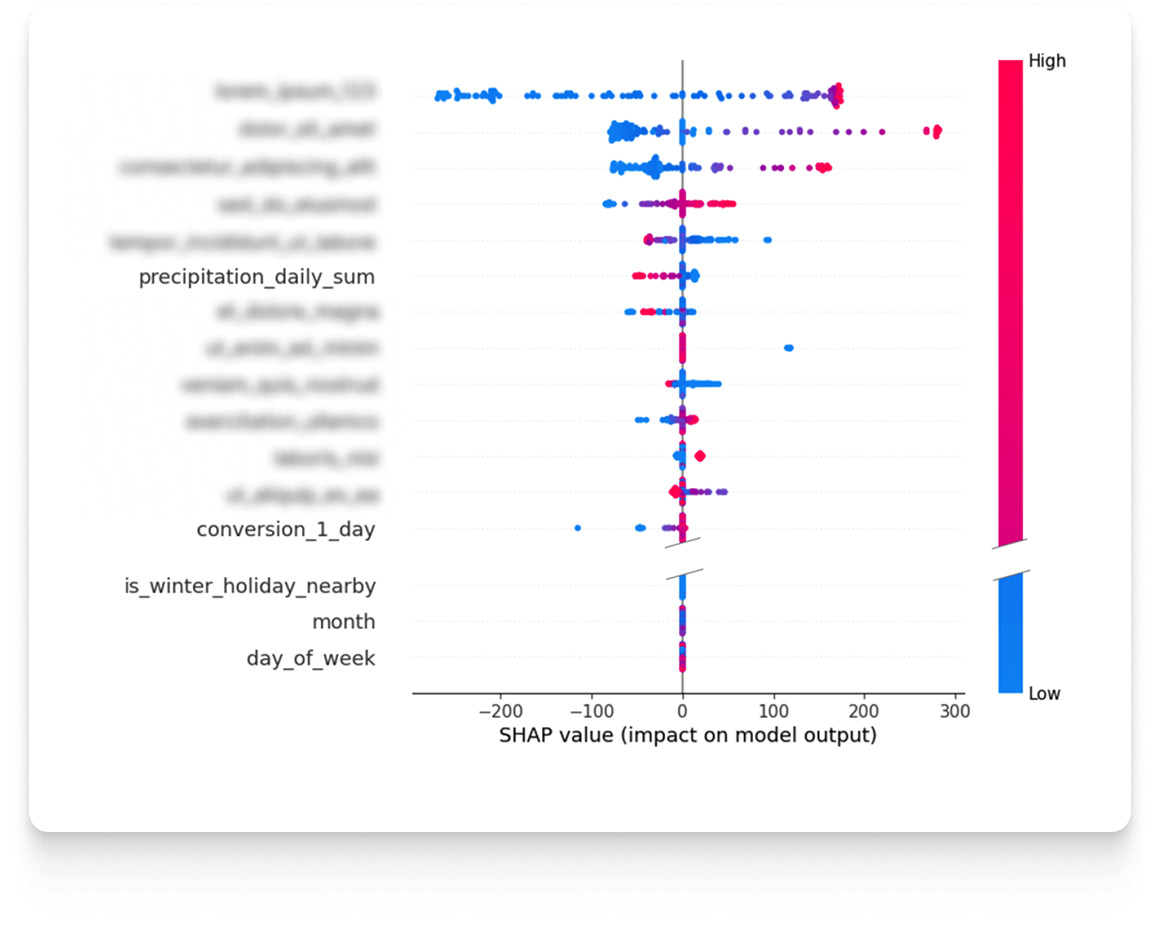
Krytycznym krokiem jest również wybór i kalibracja tzw. hiperparametrów. Są to parametry strukturalne modelu, które ustala się przed rozpoczęciem treningu i które nie ulegają zmianie w jego trakcie, lecz fundamentalnie wpływają na jego działanie. Obejmują one ustawienia ściśle związane z architekturą modelu, takie jak liczba bloków sieci neuronowej czy rozmiar warstwy wejściowej. Aby osiągnąć maksymalną skuteczność dla konkretnego horyzontu predykcji, przeprowadzanych jest setki eksperymentów. Ten iteracyjny proces optymalizacji ma na celu wyłonienie konfiguracji, która zmaksymalizuje wydajność modelu.
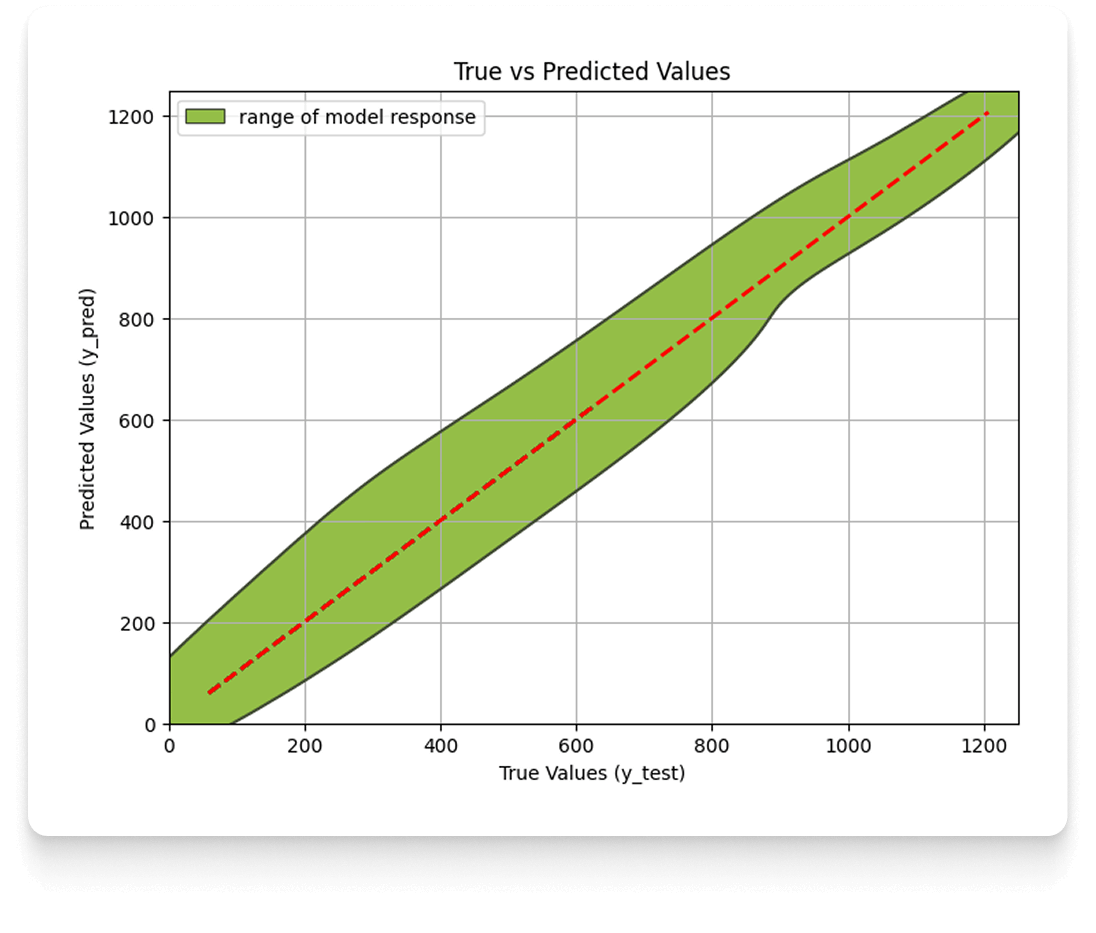
Po dobraniu hiperparametrów i wytrenowaniu modelu, niezbędnym etapem jest jego walidacja, czyli weryfikacja, czy osiąga on oczekiwany poziom precyzji i dokładności. Proces ten jest wizualizowany za pomocą wykresu wartości rzeczywistych do przewidzianych (actual vs. predicted).
Monitorowanie i Utrzymanie (Machine Learning Engineering)
Może się wydawać, że na tym praca dobiega końca, ale jest to w zasadzie początek niekończącego się cyklu, który ma za zadanie dostarczać wysokiej jakości predykcje każdego dnia. Po wytrenowaniu modelu przechodzimy do procesu automatyzacji, który obejmuje etapy walidacji, wersjonowania oraz wdrożenia modelu do środowiska produkcyjnego, czyli tam, gdzie rozwiązanie będzie dostępne dla klientów. Model jest opakowany w usługę (np. REST API), co umożliwia jego komunikację z pozostałymi elementami systemu Droplabs, takimi jak system sprzedaży. Proces ten odpowiada za automatyczne uruchamianie predykcji, zapisywanie logów oraz monitorowanie jakości działania modelu. Jako jeden z wyników końcowych, klient otrzymuje predykcje frekwencji widoczne jako wizualizacja na czytelnym panelu webowym.
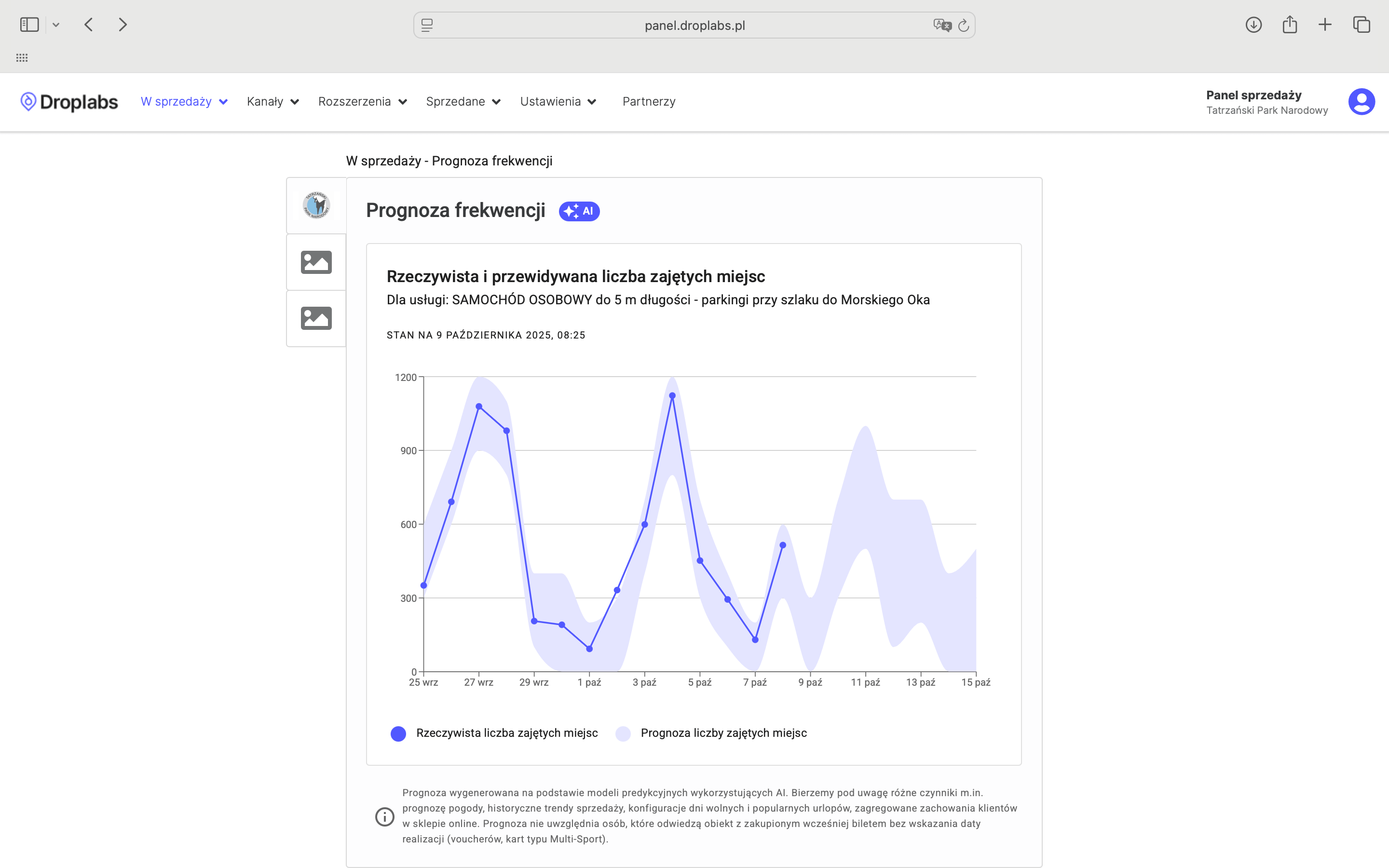
Panel pokazuje przewidywane widełki frekwencji (fioletowa strefa) oraz rzeczywistą liczbę odwiedzających (niebieskie kropki) dla terminów z przeszłości. Dzięki temu TPN może weryfikować historyczną dokładność systemu.
Po wdrożeniu, następuje trwający w trybie ciągłym etap monitorowania i utrzymania. Obejmuje to monitorowanie techniczne (wydajności serwerów) oraz monitorowanie jakości predykcji. Niezbędne jest śledzenie dryfu danych (data drifting) i dryfu modelu (model drifting).
“Zmiany takie jak modyfikacja oferty biletowej, nowe akcje marketingowe czy zmiana preferencji turystów sprawiają, że optymalne działanie modelu wymaga jego cyklicznego re-trenowania, aby jakość stale utrzymywała się powyżej zadowalającego progu.”
- dodaje Piotr Pyznarski, założyciel Droplabs odpowiadający za produkt i technologię (CTO)
Podsumowanie
Skuteczna predykcja frekwencji wymaga inżynierii AI dostosowanej do specyfiki branży atrakcji i miejsc turystycznych. Przełomem dla tej branży jest zastosowanie przez Droplabs architektury opartej na głębokich sieciach neuronowych, która działa jako model zespołowy (ensemble learning).
“Takie podejście umożliwia Droplabs stworzenie rozwiązań, które elastycznie adaptują się do konkretnych atrakcji turystycznych - w tym Tatrzańskiego Parku Narodowego. Dzięki dogłębnej eksploracji danych, specyficznych dla każdego z obiektów, jesteśmy w stanie dostarczać skutecznych predykcji frekwencji.”
- zaznacza Monika Karpierz-Nałęcz, Head of AI w Droplabs.
W Tatrzańskim Parku Narodowym widełki przewidywanej frekwencji dla nadchodzącego dnia sprawdzają się w ok. 90% przypadków.
Proces tworzenia, monitorowania i ciągłego ulepszania modeli jest złożony i wymaga zastosowania autorskich rozwiązań. Za tym, aby każdego dnia w panelu TPN pojawiały się jakościowe predykcje, czuwa cały zespół specjalistów Droplabs z różnych dziedzin: Data Science, Machine Learning Engineering, DevOps, Analityki Danych i Backend Engineering.
Ten wpis jest jedną z części szerszego artykułu "AI w służbie dziedzictwa: Dynamic Pricing Droplabs i predykcja frekwencji w kształtowaniu zrównoważonych zachowań turystycznych w TPN". Kolejna część pozwoli odkryć jak Dynamic Pricing Droplabs pomaga w kształtowaniu zachowań turystów.